
As a consultancy, we regularly take part in the development and maintenance of platforms used by a large number of people, sometimes hundreds of development teams. Engaging with so many engineers also requires sharing knowledge about processes and tools. That’s why we introduced a knowledge platform composed of modules for each subject. The primary objective of this knowledge-sharing platform is that it must be kept easy for everyone to follow, clear with its objectives and accessible to all potential users.
In this particular instance, our objective was to introduce our clients’ platform tenants to the general concept of Horizontal Pod Autoscaling (HPA) before diving deeper into the custom-built HPA solution; its functionality, what is required to enable it, what principles their application needs to abide by, along with all the prerequisite concepts to introduce HPA to developers of all backgrounds, skills and abilities.
To accommodate the required learning, we implemented this specialised learning module that introduced the users to HPA as a concept, how to use the custom HPA solution, and the means to continuously deploy and test resources, providing an easy barrier of entry and getting familiarised with the solution at their own pace. As with each learning module in the platform, we provide the users with clear objectives as to what they need to achieve to successfully complete each of the learning modules.
While going through the HPA learning module, engineers are presented with various scenarios such as variable workloads in low-demand periods, high availability in high traffic, and resource efficiency among many others. Due to the nature of the custom scaler module, the tenants are then introduced to the platform metrics that the environment and their applications are generating, followed by Prometheus; and how these can be utilised with PromQL which is the functional query language provided by Prometheus as the main way to query metrics.
The hands-on interactive experience prepared for this module guides the user through the entire process of deploying a demo reference application and gradually ramping up to the point of monitoring the application scaling up and down using a simulated workload.
Consisting of simple makefile targets provided with environmental information - such as the user name - users can set up a single pod application in a dedicated namespace, separated and isolated from the rest of the cluster resources. In practice, this ensures that other tenants would not be affected, while also conforming to their organisation’s standards and processes.
The users are then asked to expose the pod to a simulated workload, all while monitoring the performance of their pod in terms of CPU and memory for example. This is the kind of real-world behaviour that they could expect from their application when exposed to live scenarios, and given this behaviour, they can now make an informed decision about their application’s scalability limits and breakpoints.
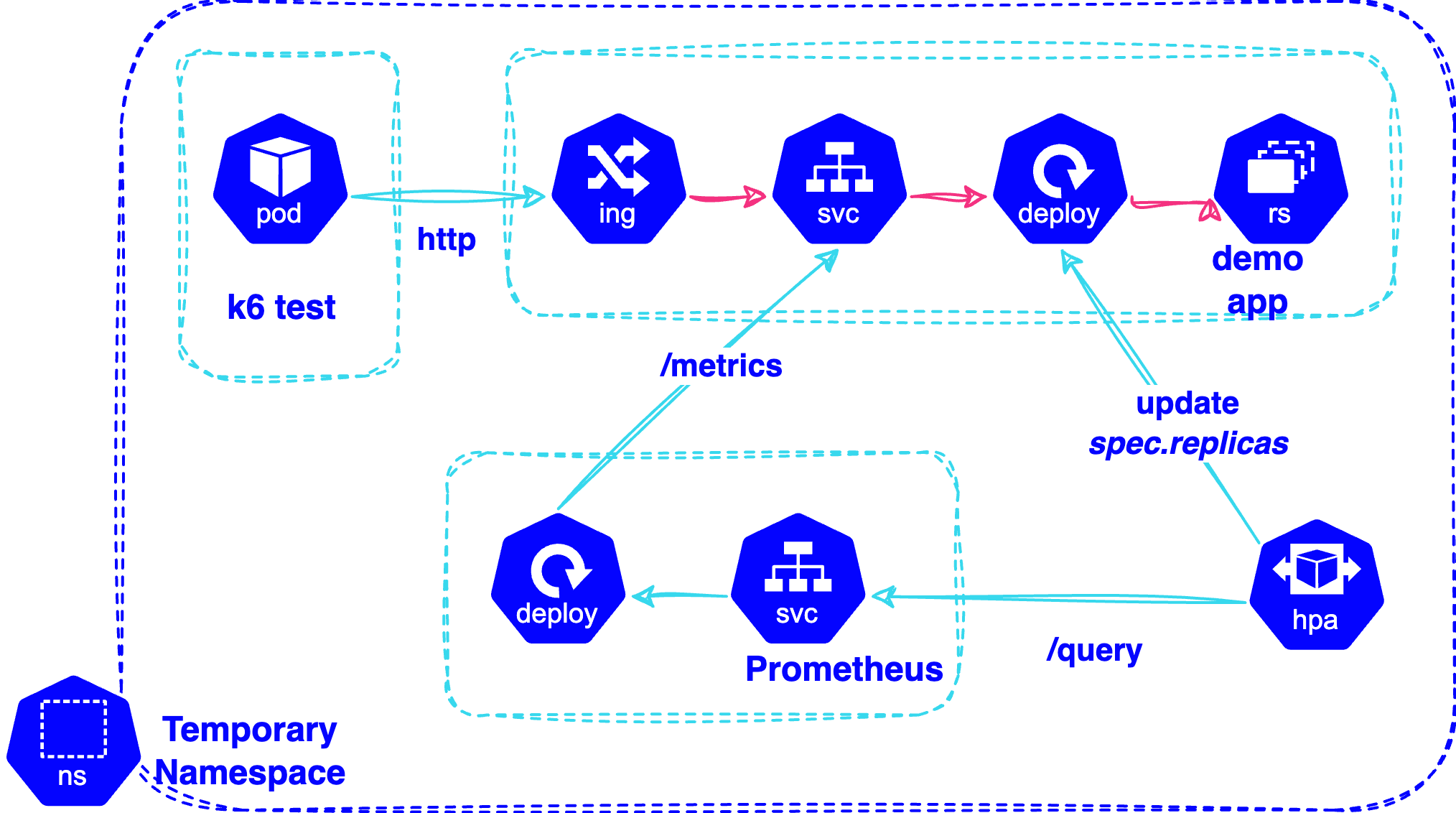
For the next part of the hands-on experience, tenants are trained on how and instructed to deploy the application, as a deployment with multiple replicas, that would also be exposed to a simulated workload. This would again monitor its behaviour, how the application scales - i.e. how many new replicas - and when the application scales - i.e. at which thresholds.
Upon completing the previous tasks, the next step is the configuration of the custom HPA resource and training on what each setting meant for the decisions the scaler module needed to make. In its basic configuration, the custom HPA solution relies on a Prometheus query, along with the threshold values that should trigger the scaling process. At this point, we covered the fundamentals of how to perform a Prometheus query over the metrics the users observed earlier.
At the end of the process, they could expose the application to scenarios they created and monitor the behaviour of the deployment.
The overall process consisted of 10 simple steps:
- Introduction to auto-scaling principles
- Why do we need a new custom solution
- Introduction to the new custom solution
- Create a hands-on environment
- Deploy the application as a single pod
- Expose the application to simulated steadily increasing load
- Find the application’s basic limitations
- Deploy the application as a deployment with the minimum replicas
- Expose the application to simulated steadily increasing load
- Understand how the custom HPA module works and construct Prometheus queries
- Deploy the custom HPA solution configured with the Prometheus and threshold values
- Expose the application to various scenarios
CECG’s knowledge platform seeks to provide knowledge at its core, exposing the user to the essence of the subject they need to scholar. We try to keep the noisy parts of the process away from the user by providing easy-to-use tools and letting the user progress through each module at their own pace with repeatable steps and clear objectives for each step of the process.
Our Knowledge Platform is used both internally and by our clients, so it is constantly updated and enriched, to cover all training needs around platform engineering as well as customised on a client-by-client case to meet our client’s unique requirements and needs with specialised modules that help our clients achieve their goals and continuously upskill their engineering teams.