
Over the last year, we built a Kubernetes-based Developer Platform for a large retail bank. A key part of any Developer Platform is baked-in security. We believe Developer Platforms make implementing security across many teams and services significantly faster and cheaper.
Context
The retail bank had a great desire to adopt containers in a structured way but hadn’t managed to do it yet.
The security department wanted to use this as an opportunity to increase the adoption of existing security standards, as well as define new standards for Cloud Native applications.
When investing in a Developer Platform, we focus on getting a small number of users in production. We’ve witnessed many platforming attempts fail, as too many features were included in the initial production release rather than focussing on adoption and then evolution.
There is an almost unlimited set of security features and maturity for those features. The right ones should be picked for a Minimum Viable Product (MVP) along with a roadmap for adding additional security features post-initial release.
Developer Platform Security
When considering security for a Developer Platform, we categorise features into:
- Build and deployment protection
- Misconfiguration
- Container vulnerability scanning
- Runtime protection
- Host endpoint protection
- Container endpoint protection
- Host vulnerability scanning
- Container vulnerability scanning
- Secrets management
- Multi-Tenant Access Control
- Network Segregation
- Encryption
- In transit
- At rest
- Corporate integrations
- Secure Kubernetes setup
This list isn’t exhaustive but it is a good start.
Secrets Management
A consistent and secure approach to secrets management is a key challenge for most organisations.
For this Developer Platform, we integrated with Cyber Ark, syncing secrets to Kubernetes Secrets at deployment time.
This is a simple approach to secret management for a Developer Platform, but not the best one, future iterations will only have secrets available at runtime, avoiding Kubernetes Secrets.
Access Control
A consistent approach to access management is a key selling point of a Developer Platform. You can be sure who can access what, and always in a standard way.
Sign-on is integrated with the corporate standard at the client of Azure AD meaning that group and user management is the same for the Developer Platform as for the rest of the bank.
Each tenant of the Developer Platform has two groups: RO and Admin. Those AD groups give access to Kubernetes roles that give the right access to that team’s namespaces. Tenant onboarding and provisioning is done with standard Kubernetes namespaces. At other clients, we have also deployed the Hierarchical Namespace Controller and in the future, we are considering using technologies such as VClusters and Capsule.
Image Vulnerability Scanning
Knowing what container images are running where and with which vulnerabilities is a key challenge for an organisation. With a mix of images from the Internet, vendors and in-house, without controls, it is nearly impossible to ensure software with vulnerabilities is not running in your organisation.
We recommend a defence in depth when it comes to vulnerability scanning:
- Build time: scan the images as they are built
- Deploy time: re-scan / have a policy for what is allowed to be deployed
- Runtime: keep re-scanning to catch vulnerabilities raised after deployment time
Scanning is just the first part. A Developer Platform needs a policy for what is allowed and where. A blanket zero vulnerabilities anywhere might sound ideal but would likely mean you can’t deliver value to your customers quickly enough.
For this Developer Platform, we implemented the following rules to deploy an image:
- All images deployed in the platform need to be scanned by Qualys.
- Images need to have been last scanned in the past 30 days - this can be achieved by either the ECR scanning that Qualys allows - however you’ll need to pay a licence per ECR which didn’t fit our use case as we had lots of ECRs. So it was achieved simply by having the runtime sensor that would continuously scan the deployed images.
- Since the images are immutable, even when promoted to different ECR, we would use the image digest to check if they have been scanned, meaning you could scan it once and deploy and promote it to all environments, because the image digest would be the same on all ECRs.
- An image with vulnerabilities with severity >3 found on an image that is trying to be deployed, if those vulnerabilities are older than 30 days, they would not be allowed. If they are newer, they would be allowed with a warning. Note that this date is the date when the vulnerability was found/reported, not when it was found on this image.
Host Vulnerability Scanning
Before the Developer Platform, every product team could run VMs in production. With the Kubernetes Developer Platform that concern is now handled by the Developer Platform team so security knows that any application running on the Developer Platform is on VMs that have Crowdstrike host vulnerability scanning enabled.
SIEM
What is SIEM (Security Information and Event Management)?
- Log management: SIEM systems gather vast amounts of data in one place, organise it, and then determine if it shows signs of a threat, attack, or breach.
- Event correlation: The data is then sorted to identify relationships and patterns to quickly detect and respond to potential threats.
- Incident monitoring and response: SIEM technology monitors security incidents across an organisation’s network and provides alerts and audits of all activity related to an incident.
There are two areas for SIEM integration for a Developer Platform:
- The Developer Platform’s own logs
- The tenant application log integration
Getting all logs of an organisation’s applications into the SIEM solution can be an impossible task. A Developer Platform allows that integration to be done once, and every application deployed can then send logs to the SIEM.
This is something that always needs to be discussed and reviewed with security. Whatever information you send, if there are no rules to interpret that information, there is no need to send those logs, it’s just a waste of space.
What information can be relevant?
Focussing here on this client’s use case, which uses AWS, Qualys, ServiceNow and Sentinel as the SIEM tool.
AWS related:
- GuardDuty - Amazon GuardDuty is a security monitoring service that analyses and processes CloudTrail event logs, VPC flow logs, and DNS logs.
- CloudTrail - monitors events on the AWS account
- CloudWatch - CloudWatch Logs to monitor, store and access your log files from EC2 instances, Route 53, EKS control plane - this includes the api-server logs.
Qualys:
- Vulnerabilities found on running images
- Malicious activity executed on the platform
The way that Qualys logs end up in Sentinel is by being consumed by ServiceNow. But since that implementation wasn’t ready for the launch, we ended up going with GitHub - falcosecurity/falco: Cloud Native Runtime Security as a temporary solution. The alerts produced by Falco were also sent to Sentinel using a logstash connector deployed inside the platform.
Container Endpoint Detection Response (EDR)
EDR monitors for suspicious or malicious activity by the containers in the platform. For this client, we used both Qualys and Falco.
jsPolicy Kubernetes Policies were used to block deployments from being created that didn’t conform to the following policies:
- Containers running with root user & group
- Images not from ECR
- Image digest that hasn’t been scanned by Qualys
- Deny host mounts
- Deny usage of the default namespace
- The creation of NodePort is not allowed
- Each resource should have the correct labels and annotations. They’re used to identify the resource in ServiceNow and inserted automatically via a Developer Platform mutating webhook copying the annotations on the namespace
- Deny deployments without resources request and limits
There are some other policies in place only warning as a set of best practices like the container must have a RO root file system.
Network Isolation
Different requirements and decisions were made to make this work. The requirement was to have a default deny network, here are some of the finer details:
App → App
Ingress default deny.
Egress default allow.
Allowing egress to avoid having redundant network policies in both namespaces.
App → Internet/Proxy service
Egress default allow.
Anything going to the internet needed to be whitelisted by the proxy service. Since there was already that rule, we allowed cluster-wide connectivity to the proxy service and if it forwards or not, that’s in the control of the proxy.
IngressController → App
Egress default allow.
Ingress default deny.
Teams needed to open connectivity on their namespace to allow connectivity from the IC. There was a debate if this should be default allowed but we decided not to.
App → Non-proxy / Internal CIDR/ Internal FQDN
This was to be used for connecting databases outside the Developer Platform.
Each tenant has their own AWS accounts and their own databases/services deployed there. To allow connectivity from the Kubernetes cluster, they need to be allowed from the whole CIDR range. The way we can restrict that work is as follows:
- There is a validating webhook that reads the configmap of allowed FQDN/CIDR range lists of each of the tenants. Meaning we map tenant X can connect to CIDR Y. If CIDR Y is not on the allowed list, we will deny the creation of the FQDN Cilium Network Policy.
For simplicity, we were also only allowing Cilium Network Policies and not regular network policies.
App → Internal Services
The platform was responsible for these ones. They would allow connectivity to the proxy service, the cluster IPs, ingress connectivity to kube-DNS and other services.
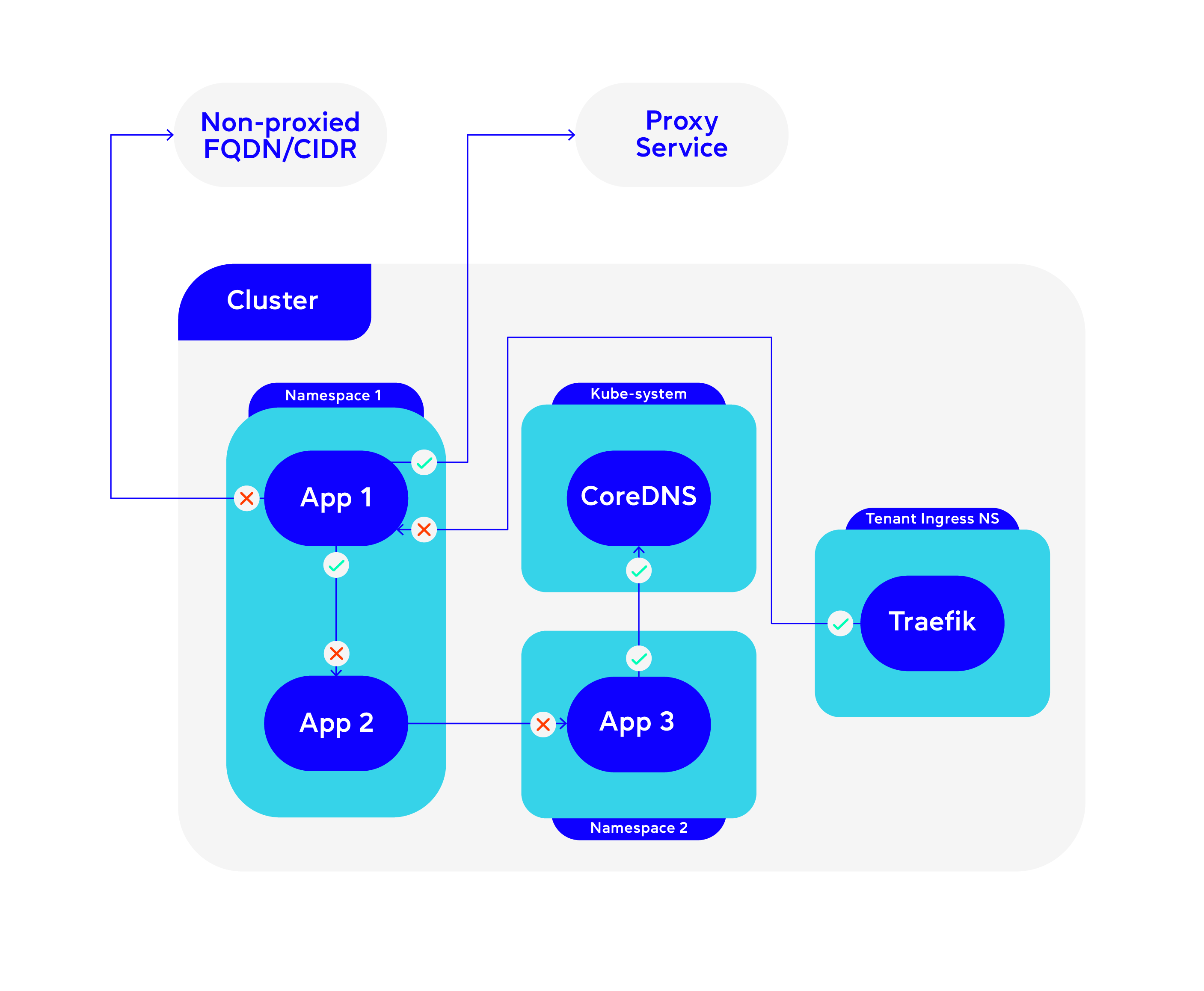
Default connectivity provided by the Platform team
What’s next?
Some features coming in the future:
- Replace Falco with Qualys runtime scanner: The Qualys runtime scanner is already deployed, but since the information isn’t being consumed by ServiceNow, only when it is, we can deprecate Falco.
- Block images with vulnerabilities older than 30 days.
- Monitoring and alerts improvements.
- Improve the lifecycle of the FQDN/CIDR requests. This should be coming through service now firewall requests and updated automatically without the platform’s involvement.